QRAFT Protocol Description
QLuster is built on the RAFT protocol, but with significant modifications:
-
the protocol was specialized for broadcast networks (udp multicast was chosen as the transport method) — node interactions are not p2p, and each node sees all messages sent by other nodes;
- due to the fundamental unreliability of udp multicast, the possibility of rpc message loss was taken into account;
-
a pre-voting voting stage has been added, eliminating the occurrence of “flickering”;
-
voting have been significantly redesigned:
- the "candidate" node status (nodes can be either leaders or replicas) and the corresponding rpc messages have been removed;
- the node with the largest commit index (lsn) is selected whenever possible;
- in the case of failed voting, there is no need for a random delay;
-
added protection against split-brain (a situation where multiple leaders exist simultaneously in a cluster).
What remained unchanged:
-
Basic concepts of the RAFT protocol: term, commit index, applied index;
-
Log replication mechanism.
Features of Broadcast Transport
-
Each node sees all messages sent by other nodes, but some messages may be lost.
-
Each cluster node monitors connectivity with other nodes by recording the time of the last message from each node, and if this time exceeds the timeout, it adds that node to the missing list.
-
Every rpc message includes a header in which the node reports its state:
- term;
- commit index — lsn;
- applied index — the first index that was not applied to the state machine;
- minimum index — the first log index contained in the log file;
- cluster leader ID;
- missing list.
This approach allows each node to monitor the state of all cluster nodes and make a more informed decision during the leader voting stage.
Leader Election
Figure 1. Cluster node state transition diagram
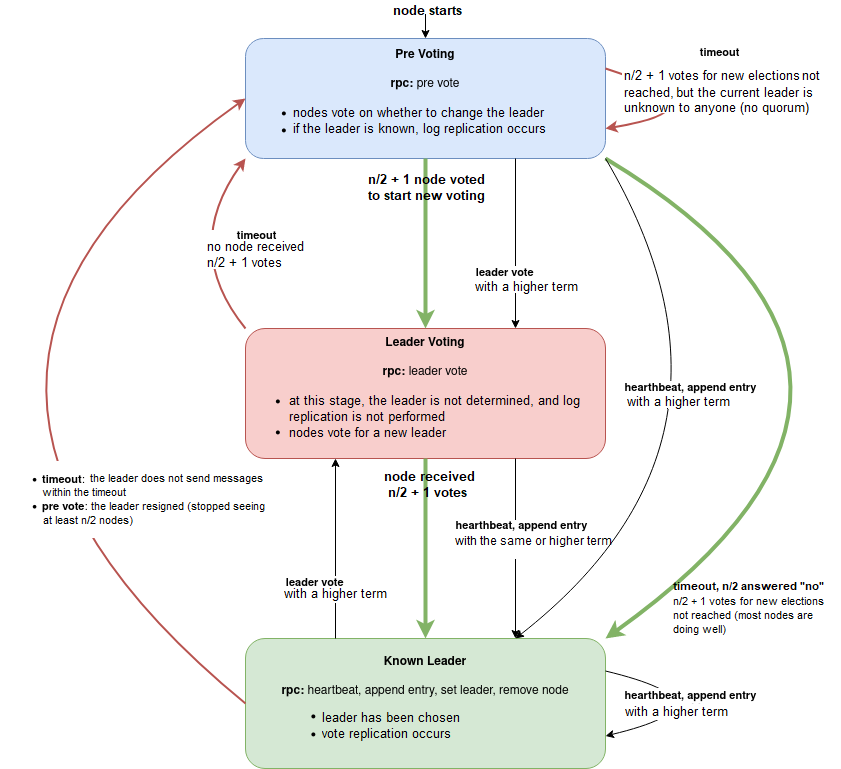
Pre Voting
The original RAFT has a "flickering" problem: if one node has poor connectivity, it initiates a leader voting and wins, after which the entire cluster begins to experience problems.
To avoid this scenario, we introduced a pre-voting stage, in which nodes vote to do a voting, or a majority of nodes are doing well.
At this stage, term is NOT incremented, so the leader's work and replication are not interrupted.
If the required number of votes is not reached within the prevoting timeout, the node that initiated the vote accepts the current leader (the node with the maximum number of leader mentions in rpc message headers).
If n/2 + 1 nodes vote for a new voting, then all nodes increase their term and move to the Leader Voting state.
Leader Voting
-
At the Pre Voting stage, all nodes update their commit index and missing list.
-
Each node sorts the list of all cluster nodes in descending order by the following values:
- commit index,
- node ID;
-
nodes that are not visible to the voting node are filtered out;
-
nodes that are not visible to half the cluster or more are filtered out;
-
the vote is cast for the first node in the list; if the list is empty, the node votes for itself.
This approach leverages the benefits of broadcast transport and eliminates "candidates" and random delays.
Features of a Leader Work
Log Replication
The log replication mechanism is taken entirely from RAFT without modification.
Our implementation supports both weak and strong replication, using parameter replication factor — the number of nodes which a log should be replicated to before it can be applied to the state and before incrementing the applied index value.
Hearthbeat
If the leader has no logs to replicate, it sends an rpc Hearthbeat to convey its current status and indicate that it is alive.
Nodes that receive a Hearthbeat from the leader also send a Hearthbeat.
Resignation
Without a Successor
If the leader's missing list contains more than half of the cluster nodes, the leader voluntarily relinquishes its authority. It also sends an rpc PreVote to notify the other cluster nodes of this. Upon receiving the PreVote from the leader, the nodes immediately begin voting for a new leader.
With a Successor
If an administrator plans to manually switch the leader in a cluster, the leader generates a SetLeader log specifying the successor node.
Automatic Removal of Nodes From the Cluster
If a cluster node is on the missing list of n/2 + 1 nodes in the cluster, the leader automatically generates a RemoveNode log to remove it from the cluster.
You can also specify a minimum number of nodes in the cluster (5 by default) at which automatic removal stops.
RPC Messages
Hearthbeat
For clarity and convenience, the heartbeat is separated into a separate RPC (in RAFT, it's an AppendEntry without a log).
There is no request/reply split; receivers can determine that the message was sent by the leader and requires a response.
AppendEntry/AppendEntryReply
The leader sends AppendEntry to replicate the log to the other nodes. Nodes that receive this message attempt to replicate the log and respond with a status.
AppendEntry parameters:
- prev log index;
- prev log term;
- log term;
- log.
AppendEntryReply parameters:
- log index;
- success (yes/no).
PreVote/PreVoteReply
PreVote is sent by a node that hasn't seen messages from the leader for a timeout period. It doesn't switch term.
Each node that receives PreVote responds with PreVoteReply.
PreVoteReply parameters:
- agree (yes/no) — a vote for or against holding a leader voting.
LeaderVote
By sending this message, the node votes for a new leader.
In RAFT, this is RequestVote/RequestVoteReply, but since we don't have any candidates, the request/reply split is not required.
Parameters:
- candidate — ID of the node being voted on.
Cluster Logs
AddNode
Introducing a new node to the cluster.
RemoveNode
Sent by the leader when a node needs to be removed from the cluster.
Parameters:
- id — ID of the node being removed from the cluster.
SetLeader
Leader change in the cluster.
Parameters:
- leader — successor node that will become the new leader.
SetConfiguration
Updating cluster settings. All settings are sent in a single log.
QhbReady/QhbDown
Sent by a node, signals the state of the node's database.
LeaderReady
Sent by the new leader after the database has been brought into a usable master state.
Manual Leader Change
-
A SetLeader log is sent specifying the new leader ID.
-
The current (old) leader enters leader transition mode and no longer accepts new logs.
-
The current leader continues replicating logs and waits for a heartbeat from the new leader with an incremented term.
-
If the leader transition does not occur within the timeout, the old leader increments term by 2 and remains the leader.