Genetic Query Optimizer
Author
Written by Martin Utesch (utesch@aut.tu-freiberg.de) for the Institute of Automatic Control at the University of Mining and Technology in Freiberg, Germany.
Query Handling as a Complex Optimization Problem
Among all relational operators the most difficult one to process and optimize is the join. The number of possible query plans grows exponentially with the number of joins in the query. Further optimization effort is caused by the support of a variety of join methods (e.g., nested loop, hash join, merge join in QHB) to process individual joins and a diversity of indexes (e.g., B-tree, hash, GiST and GIN in QHB) as access paths for relations.
The normal QHB query optimizer performs a near-exhaustive search over the space of alternative strategies. This algorithm, first introduced in IBM's System R database, produces a near-optimal join order, but can take an enormous amount of time and memory space when the number of joins in the query grows large. This makes the ordinary QHB query optimizer inappropriate for queries that join a large number of tables.
In the following we describe the implementation of a genetic algorithm to solve the join ordering problem in a manner that is efficient for queries involving large numbers of joins.
Genetic Algorithms
The genetic algorithm (GA) is a heuristic optimization method which operates through randomized search. The set of possible solutions for the optimization problem is considered as a population of individuals. The degree of adaptation of an individual to its environment is specified by its fitness.
The coordinates of an individual in the search space are represented by chromosomes, in essence a set of character strings. A gene is a subsection of a chromosome which encodes the value of a single parameter being optimized. Typical encodings for a gene could be binary or integer.
Through simulation of the evolutionary operations recombination, mutation, and selection new generations of search points are found that show a higher average fitness than their ancestors. Figure 1 illustrates these steps.
Figure 1. Structure of a Genetic Algorithm
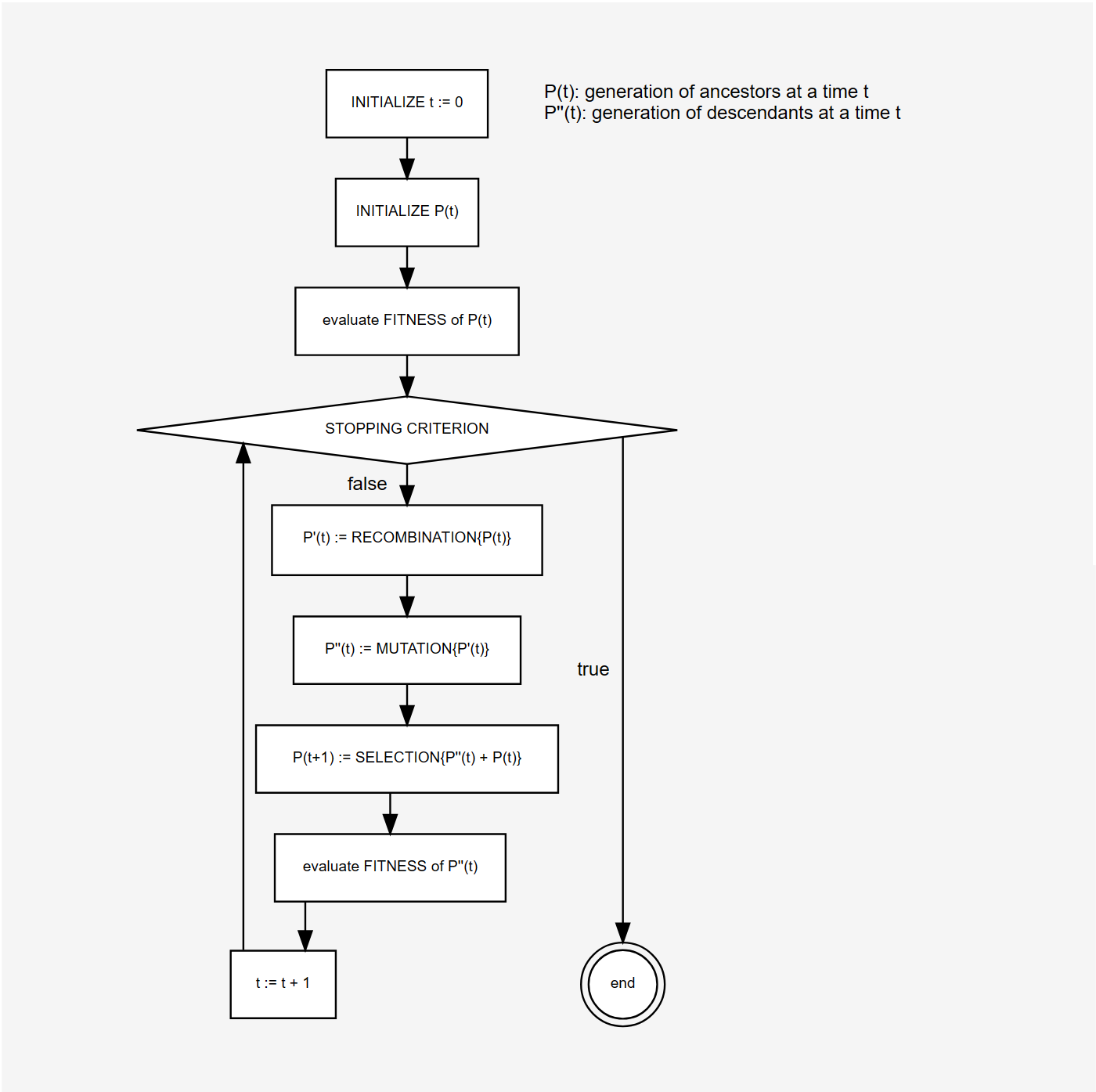
According to the comp.ai.genetic FAQ it cannot be stressed too strongly that a GA is not a pure random search for a solution to a problem. A GA uses stochastic processes, but the result is distinctly non-random (better than random).
Genetic Query Optimization (GEQO) in QHB
The GEQO module approaches the query optimization problem as though it were the well-known traveling salesman problem (TSP). Possible query plans are encoded as integer strings. Each string represents the join order from one relation of the query to the next. For example, the join tree
/\
/\ 2
/\ 3
4 1
is encoded by the integer string '4-1-3-2', which means, first join relation '4' and '1', then '3', and then '2', where 1, 2, 3, 4 are relation IDs within the QHB optimizer.
Specific characteristics of the GEQO implementation in QHB are:
-
Usage of a steady state GA (replacement of the least fit individuals in a population, not whole-generational replacement) allows fast convergence towards improved query plans. This is essential for query handling with reasonable time;
-
Usage of edge recombination crossover which is especially suited to keep edge losses low for the solution of the TSP by means of a GA;
-
Mutation as genetic operator is deprecated so that no repair mechanisms are needed to generate legal TSP tours.
Parts of the GEQO module are adapted from D. Whitley's Genitor algorithm.
The GEQO module allows the QHB query optimizer to support large join queries effectively through non-exhaustive search.
Generating Possible Plans with GEQO
The GEQO planning process uses the standard planner code to generate plans for scans of individual relations. Then join plans are developed using the genetic approach. As shown above, each candidate join plan is represented by a sequence in which to join the base relations. In the initial stage, the GEQO code simply generates some possible join sequences at random. For each join sequence considered, the standard planner code is invoked to estimate the cost of performing the query using that join sequence. (For each step of the join sequence, all three possible join strategies are considered; and all the initially-determined relation scan plans are available. The estimated cost is the cheapest of these possibilities.) Join sequences with lower estimated cost are considered “more fit” than those with higher cost. The genetic algorithm discards the least fit candidates. Then new candidates are generated by combining genes of more-fit candidates — that is, by using randomly-chosen portions of known low-cost join sequences to create new sequences for consideration. This process is repeated until a preset number of join sequences have been considered; then the best one found at any time during the search is used to generate the finished plan.
This process is inherently nondeterministic, because of the randomized choices made during both the initial population selection and subsequent “mutation” of the best candidates. To avoid surprising changes of the selected plan, each run of the GEQO algorithm restarts its random number generator with the current geqo_seed parameter setting. As long as geqo_seed and the other GEQO parameters are kept fixed, the same plan will be generated for a given query (and other planner inputs such as statistics). To experiment with different search paths, try changing geqo_seed.
Future Implementation Tasks for QHB GEQO
Work is still needed to improve the genetic algorithm parameter settings.
While looking for solution to the query optimization problem by means of a GA (routines gimme_pool_size and gimme_number_generations) we have to find a compromise for the parameter settings to satisfy two competing demands:
-
Optimality of the query plan
-
Computing time
For example:
/*
* Configuration options
*/
int Geqo_effort;
int Geqo_pool_size;
int Geqo_generations;
double Geqo_selection_bias;
double Geqo_seed;
static int gimme_pool_size(int nr_rel);
static int gimme_number_generations(int pool_size);
/* complain if no recombination mechanism is #define'd */
#if !defined(ERX) && \
!defined(PMX) && \
!defined(CX) && \
!defined(PX) && \
!defined(OX1) && \
!defined(OX2)
#error "must choose one GEQO recombination mechanism in geqo.h"
#endif
/*
* geqo
* solution of the query optimization problem
* similar to a constrained Traveling Salesman Problem (TSP)
*/
RelOptInfo *
geqo(PlannerInfo *root, int number_of_rels, List *initial_rels)
{
GeqoPrivateData private;
int generation;
Chromosome *momma;
Chromosome *daddy;
Chromosome *kid;
Pool *pool;
int pool_size,
number_generations;
#ifdef GEQO_DEBUG
int status_interval;
#endif
Gene *best_tour;
RelOptInfo *best_rel;
#if defined(ERX)
Edge *edge_table; /* list of edges */
int edge_failures = 0;
#endif
#if defined(CX) || defined(PX) || defined(OX1) || defined(OX2)
City *city_table; /* list of cities */
#endif
#if defined(CX)
int cycle_diffs = 0;
int mutations = 0;
#endif
/* set up private information */
root->join_search_private = (void *) &private;
private.initial_rels = initial_rels;
/* initialize private number generator */
geqo_set_seed(root, Geqo_seed);
/* set GA parameters */
pool_size = gimme_pool_size(number_of_rels);
number_generations = gimme_number_generations(pool_size);
#ifdef GEQO_DEBUG
status_interval = 10;
#endif
/* allocate genetic pool memory */
pool = alloc_pool(root, pool_size, number_of_rels);
/* random initialization of the pool */
random_init_pool(root, pool);
/* sort the pool according to cheapest path as fitness */
sort_pool(root, pool); /* we have to do it only one time, since all
* kids replace the worst individuals in
* future (-> geqo_pool.c:spread_chromo ) */
#ifdef GEQO_DEBUG
elog(DEBUG1, "GEQO selected %d pool entries, best %.2f, worst %.2f",
pool_size,
pool->data[0].worth,
pool->data[pool_size - 1].worth);
#endif
/* allocate chromosome momma and daddy memory */
momma = alloc_chromo(root, pool->string_length);
daddy = alloc_chromo(root, pool->string_length);
#if defined (ERX)
#ifdef GEQO_DEBUG
elog(DEBUG2, "using edge recombination crossover [ERX]");
#endif
/* allocate edge table memory */
edge_table = alloc_edge_table(root, pool->string_length);
#elif defined(PMX)
#ifdef GEQO_DEBUG
elog(DEBUG2, "using partially matched crossover [PMX]");
#endif
/* allocate chromosome kid memory */
kid = alloc_chromo(root, pool->string_length);
#elif defined(CX)
#ifdef GEQO_DEBUG
elog(DEBUG2, "using cycle crossover [CX]");
#endif
/* allocate city table memory */
kid = alloc_chromo(root, pool->string_length);
city_table = alloc_city_table(root, pool->string_length);
#elif defined(PX)
#ifdef GEQO_DEBUG
elog(DEBUG2, "using position crossover [PX]");
#endif
/* allocate city table memory */
kid = alloc_chromo(root, pool->string_length);
city_table = alloc_city_table(root, pool->string_length);
#elif defined(OX1)
#ifdef GEQO_DEBUG
elog(DEBUG2, "using order crossover [OX1]");
#endif
/* allocate city table memory */
kid = alloc_chromo(root, pool->string_length);
city_table = alloc_city_table(root, pool->string_length);
#elif defined(OX2)
#ifdef GEQO_DEBUG
elog(DEBUG2, "using order crossover [OX2]");
#endif
/* allocate city table memory */
kid = alloc_chromo(root, pool->string_length);
city_table = alloc_city_table(root, pool->string_length);
#endif
/* my pain main part: */
/* iterative optimization */
for (generation = 0; generation < number_generations; generation++)
{
/* SELECTION: using linear bias function */
geqo_selection(root, momma, daddy, pool, Geqo_selection_bias);
#if defined (ERX)
/* EDGE RECOMBINATION CROSSOVER */
gimme_edge_table(root, momma->string, daddy->string, pool->string_length, edge_table);
kid = momma;
/* are there any edge failures ? */
edge_failures += gimme_tour(root, edge_table, kid->string, pool->string_length);
#elif defined(PMX)
/* PARTIALLY MATCHED CROSSOVER */
pmx(root, momma->string, daddy->string, kid->string, pool->string_length);
#elif defined(CX)
/* CYCLE CROSSOVER */
cycle_diffs = cx(root, momma->string, daddy->string, kid->string, pool->string_length, city_table);
/* mutate the child */
if (cycle_diffs == 0)
{
mutations++;
geqo_mutation(root, kid->string, pool->string_length);
}
#elif defined(PX)
/* POSITION CROSSOVER */
px(root, momma->string, daddy->string, kid->string, pool->string_length, city_table);
#elif defined(OX1)
/* ORDER CROSSOVER */
ox1(root, momma->string, daddy->string, kid->string, pool->string_length, city_table);
#elif defined(OX2)
/* ORDER CROSSOVER */
ox2(root, momma->string, daddy->string, kid->string, pool->string_length, city_table);
#endif
/* EVALUATE FITNESS */
kid->worth = geqo_eval(root, kid->string, pool->string_length);
/* push the kid into the wilderness of life according to its worth */
spread_chromo(root, kid, pool);
#ifdef GEQO_DEBUG
if (status_interval && !(generation % status_interval))
print_gen(stdout, pool, generation);
#endif
}
#if defined(ERX)
#if defined(GEQO_DEBUG)
if (edge_failures != 0)
elog(LOG, "[GEQO] failures: %d, average: %d",
edge_failures, (int) number_generations / edge_failures);
else
elog(LOG, "[GEQO] no edge failures detected");
#else
/* suppress variable-set-but-not-used warnings from some compilers */
(void) edge_failures;
#endif
#endif
#if defined(CX) && defined(GEQO_DEBUG)
if (mutations != 0)
elog(LOG, "[GEQO] mutations: %d, generations: %d",
mutations, number_generations);
else
elog(LOG, "[GEQO] no mutations processed");
#endif
#ifdef GEQO_DEBUG
print_pool(stdout, pool, 0, pool_size - 1);
#endif
#ifdef GEQO_DEBUG
elog(DEBUG1, "GEQO best is %.2f after %d generations",
pool->data[0].worth, number_generations);
#endif
/*
* got the cheapest query tree processed by geqo; first element of the
* population indicates the best query tree
*/
best_tour = (Gene *) pool->data[0].string;
best_rel = gimme_tree(root, best_tour, pool->string_length);
if (best_rel == NULL)
elog(ERROR, "geqo failed to make a valid plan");
/* DBG: show the query plan */
#ifdef NOT_USED
print_plan(best_plan, root);
#endif
/* ... free memory stuff */
free_chromo(root, momma);
free_chromo(root, daddy);
#if defined (ERX)
free_edge_table(root, edge_table);
#elif defined(PMX)
free_chromo(root, kid);
#elif defined(CX)
free_chromo(root, kid);
free_city_table(root, city_table);
#elif defined(PX)
free_chromo(root, kid);
free_city_table(root, city_table);
#elif defined(OX1)
free_chromo(root, kid);
free_city_table(root, city_table);
#elif defined(OX2)
free_chromo(root, kid);
free_city_table(root, city_table);
#endif
free_pool(root, pool);
/* ... clear root pointer to our private storage */
root->join_search_private = NULL;
return best_rel;
}
/*
* Return either configured pool size or a good default
*
* The default is based on query size (no. of relations) = 2^(QS+1),
* but constrained to a range based on the effort value.
*/
static int
gimme_pool_size(int nr_rel)
{
double size;
int minsize;
int maxsize;
/* Legal pool size *must* be at least 2, so ignore attempt to select 1 */
if (Geqo_pool_size >= 2)
return Geqo_pool_size;
size = pow(2.0, nr_rel + 1.0);
maxsize = 50 * Geqo_effort; /* 50 to 500 individuals */
if (size > maxsize)
return maxsize;
minsize = 10 * Geqo_effort; /* 10 to 100 individuals */
if (size < minsize)
return minsize;
return (int) ceil(size);
}
/*
* Return either configured number of generations or a good default
*
* The default is the same as the pool size, which allows us to be
* sure that less-fit individuals get pushed out of the breeding
* population before the run finishes.
*/
static int
gimme_number_generations(int pool_size)
{
if (Geqo_generations > 0)
return Geqo_generations;
return pool_size;
}
In the current implementation, the fitness of each candidate join sequence is estimated by running the standard planner's join selection and cost estimation code from scratch. To the extent that different candidates use similar sub-sequences of joins, a great deal of work will be repeated. This could be made significantly faster by retaining cost estimates for sub-joins. The problem is to avoid expending unreasonable amounts of memory on retaining that state.
At a more basic level, it is not clear that solving query optimization with a GA algorithm designed for TSP is appropriate. In the TSP case, the cost associated with any substring (partial tour) is independent of the rest of the tour, but this is certainly not true for query optimization. Thus it is questionable whether edge recombination crossover is the most effective mutation procedure.
Further Reading
The following resources contain additional information about genetic algorithms:
-
The Hitch-Hiker's Guide to Evolutionary Computation (FAQ for news://comp.ai.genetic)
-
Evolutionary Computation and its application to art and design, by Craig Reynolds
-
Fundamentals of Database Systems. Sixth Edition. Ramez Elmasri and Shamkant B. Navathe. Addison-Wesley. 2011.
-
The design and implementation of the POSTGRES query optimizer. Zelaine Fong. University of California, Berkeley, Computer Science Department.