Индексы GIN
- Введение
- Встроенные классы операторов
- Расширяемость
- Реализация
- GIN советы и хитрости
- Ограничения
- Примеры
Введение
GIN расшифровывается как «Generalized Inverted Index» (Обобщённый инвертированный индекс). GIN предназначается для случаев, когда индексируемые значения являются составными, а запросы, на обработку которых рассчитан индекс, ищут по наличию элементов в этих составных объектах. Например, такими объектами могут быть документы, а запросы могут выполнять поиск документов, содержащих определённые слова.
В этом разделе мы используем термин объект или элемент, говоря о составном значении, которое индексируется, и термин ключ, говоря о включённом в него элементе. GIN всегда хранит и ищет ключи, а не объекты как таковые.
Индекс GIN хранит пары (ключ => набор-строк), где набор-строк содержит идентификаторы строк, в которых есть данный ключ. Один и тот же идентификатор строки может фигурировать в нескольких списках, так как объект может содержать больше одного ключа. Значение каждого ключа хранится только один раз, так что индекс GIN очень компактен в случаях, когда один ключ встречается много раз.
GIN является обобщённым в том смысле, что ядро GIN не знает о конкретных операциях, которые он ускоряет. Конкретная семантика определяется вспомогательными методами (стратегиями), которые управляют тем, как извлекаются ключи из индексируемых объектов и условий запросов, и как установить, действительно ли удовлетворяет запросу строка, содержащая некоторые значения ключей. Как и GiST, GIN позволяет разрабатывать дополнительные типы данных с соответствующими методами доступа экспертам в предметной области типа данных.
Встроенные классы операторов
Основной дистрибутив QHB включает классы операторов GIN, показанные в следующей таблице. Некоторые из расширений, перечисленные в примерах, предоставляют дополнительные классы операторов GIN.
| Имя | Индексированный Тип Данных | Индексируемые Операторы |
|---|---|---|
| array_ops | anyarray | && = @< |
| jsonb_ops | jsonb | ? ?& ? @> @? @@ |
| jsonb_path_ops | jsonb | @> @? @@ |
| tsvector_ops | tsvector | @@ @@@ |
Из двух классов операторов для типа jsonb, jsonb_ops это значение по умолчанию. jsonb_path_ops поддерживает меньшее количество операторов, но обеспечивает лучшую производительность для этих операторов. Дополнительную информацию смотрите в разделе Индексация jsonb.
Расширяемость
Интерфейс GIN имеет высокий уровень абстракции, требующий от автора метода доступа только реализации семантики типа данных, с которым происходит работа. Слой GIN сам заботится о параллелизме, журналировании и поиске в древовидной структуре.
Все, что требуется для работы метода доступа GIN — это реализовать несколько пользовательских методов, которые определяют поведение ключей в дереве и отношения между ключами, индексируемыми элементами и индексируемыми запросами. Короче говоря, GIN сочетает расширяемость с универсальностью, повторным использованием кода и чистым интерфейсом.
Два метода, которые обязан предоставить класс операторов для GIN:
-
extractValue
Прототип метода на C:
Datum *extractValue(Datum itemValue, int32 *nkeys, bool **nullFlags)Возвращает массив ключей (выделенный с помощью palloc) индексируемого объекта. Количество возвращаемых ключей должно быть сохранено в *nkeys. Если какой-то из ключей может быть NULL, то необходимо также заполнить nullFlags (это массив типа bool длиной *nkeys, true означает, что этот ключ NULL; аллокировать тоже
palloc'ом). Если все ключи не NULL, то можно оставить *nullFlags нулевым. Возвращаемое значение тоже может быть нулевым, если объект вообще не содержит ключей. -
extractQuery
Прототип метода на C:
Datum *extractQuery(Datum query, int32 *nkeys, StrategyNumber n, bool **pmatch, Pointer **extra_data, bool **nullFlags, int32 *searchMode)Возвращает массив ключей (выделенный с помощью palloc) для запроса. query — это правый аргумент индексируемого оператора, где левый аргумент — это индексируемый столбец. Аргумент
nзадаёт номер стратегии оператора в классе операторов (см. раздел Стратегии методов индексов). Разные операторы могут иметь разный тип правой части, и, соответственно, query может быть разного типа — и даже при одинаковом типе запрос может интерпретироваться по-разному для разных операторов. Для различения и нужен параметрn.Количество возвращаемых ключей должно быть записано в *nkeys. Если какой-то из ключей может быть
NULL, то необходимо также заполнить nullFlags (это массив типа bool длиной *nkeys, true означает, что этот ключ NULL; аллокировать тожеpalloc'ом). Если все ключи неNULL, то можно оставить *nullFlags нулевым. Возвращаемое значение тоже может быть нулевым, если объект вообще не содержит ключей.Выходной аргумент searchMode позволяет функции extractQuery выбрать режим, в котором должен выполняться поиск. Если *searchMode установить в GIN_SEARCH_MODE_DEFAULT (это значение уже установлено перед вызовом), подходящими кандидатами считаются объекты, которые соответствуют хотя бы одному из возвращённых ключей. Если *searchMode установить в GIN_SEARCH_MODE_INCLUDE_EMPTY, то в дополнение к объектам с минимум одним совпадением ключа, подходящими кандидатами будут считаться и объекты, вообще не содержащие ключей. (Этот режим полезен для реализации, например, оператора является-подмножеством). Если *searchMode установить в GIN_SEARCH_MODE_ALL, подходящими кандидатами считаются все отличные от
NULLобъекты в индексе, независимо от того, встречаются ли в них возвращаемые ключи. (Этот режим намного медленнее других, так как он по сути требует сканирования всего индекса, но он может быть необходим для корректной обработки крайних случаев. Оператор, который часто выбирает этот режим, скорее всего не подходит для реализации в классе операторов GIN).Выходной аргумент pmatch используется, когда поддерживаются частичные ключи в запросах. Выделите массив из *nkeys элементов типа bool и задайте значение true для тех ключей, для которых выделенный ключ является частичным. Если *pmatch нулевой (а он нулевой перед вызовом), GIN полагает, что все ключи точные, а не частичные.
Выходной аргумент extra_data используется, чтобы привязать к каждому ключу дополнительную информацию, которая будет передана в методы consistent и comparePartial. Поместите в *extra_data массив из из *nkeys указателей на объекты производного типа. Перед вызовом указатель *extra_data нулевой, поэтому просто игнорируйте его, если не надо никакой дополнительной информации. Если массив *extra_data задан, то он передаётся в метод consistent целиком, а в comparePartial передаётся один соответствующий элемент.
Класс операторов должен также предоставить функцию для проверки, соответствует ли индексированный объект запросу. Поддерживаются две её вариации: булевская consistent и triConsistent с трехзначным результатом. Если предоставлена только consistent, то некоторые оптимизации, построенные на отбраковывании объектов до выборки всех ключей, отключаются. Если предоставлена только triConsistent, то она будет использоваться и вместо consistent, т.к. является более общей. Однако, если вычисление булевской вариации дешевле, то имеет смысл реализовать обе.
-
consistent
Прототип метода на C:
bool consistent(bool check[], StrategyNumber n, Datum query, int32 nkeys, Pointer extra_data[], bool *recheck, Datum queryKeys[], bool nullFlags[])Возвращает true, если индексированный элемент удовлетворяет оператору запроса с номером стратегии
n(или "возможно удовлетворяет", если дополнительно ставится флаг перепроверки). Проиндексированное значение в этом методе не доступно (GIN их нигде не хранит), есть только информация, какие из ключей запроса встретились в данном кортеже индекса. В метод передаётся всё, что вернула extractQuery при разборе запроса: массив ключей queryKeys, какие из нихNULL— nullFlags, дополнительную информацию extra_data, но главное — какие из этих ключей присутствуют в текущем кортеже индекса: check. Все эти массивы имеют длину nkeys, если ненулевые. На всякий случай передаётся и оригинальный запрос query.Если extractQuery выдала NULL-ключ, и в кортеже тоже есть NULL-ключ, то считается, что ключ найден (что является нетипичным при обработке
NULL-значений, и похоже на семантику IS NOT DISTINCT FROM). Если с точки зрения вашего класса операторов это особенная ситуация, то, встретивcheck[i] == true, вы можете проверитьnullFlags[i], чтобы понять, было ли это попадание в NULL-ключ. В случае положительного результата флаг *recheck следует оставить false, если вы уверены, что строка подходит, или выставить true, чтобы оператор перепроверили на данных, взятых из строки таблицы из кучи. -
triConsistent
Прототип метода на C:
GinTernaryValue triConsistent(GinTernaryValue check[], StrategyNumber n, Datum query, int32 nkeys, Pointer extra_data[], Datum queryKeys[], bool nullFlags[])Метод похож на consistent, но результат и входной аргумент check имеют тип GinTernaryValue, который состоит из 3-х вариантов: GIN_TRUE, GIN_FALSE и GIN_MAYBE. GIN_MAYBE означает "может быть подходит". Вы должны руководствоваться общими правилами тернарной логики: возвращать GIN_TRUE, только если строка подходит под запрос в предположении "худшего случая" для ключей, которые GIN_MAYBE, т.е. предполагая, что они все не подходят. И наоборот, возвращать GIN_FALSE, только если строка не подходит, даже в "лучшем случае" для GIN_MAYBE-ключей.
Выходного параметра recheck нет, вместо этого результат GIN_MAYBE трактуется как "надо перепроверить", а GIN_TRUE как "точно подходит".
Далее, ядру GIN нужно уметь сортировать ключи. Вы можете предоставить функцию сортировки compare. Если вы этого не сделаете, то GIN будет использовать сортировку по умолчанию для соответствующего типа данных.
-
compare
Прототип метода на C:
int compare(Datum a, Datum b)Сравнивать два ключа (а не исходных индексируемых значения) и вернуть целое число
< 0/0/> 0, когда первый ключ меньше/равен/больше второго. NULL-ключи никогда не передаются в эту функцию.
И ещё один необязательный метод:
-
comparePartial
Прототип метода на C:
int comparePartial(Datum partial_key, Datum key, StrategyNumber n, Pointer extra_data)Осуществляет проверку соответствия ключа индекса частичному ключу запроса. Результат 0 означает, что ключ подходит; меньше нуля — не подходит, но следует продолжить сканировать ключи; больше нуля — следует прекратить сканирование набора ключей, т.к. все остальные точно не подходят. NULL-ключи никогда не передаются в эту функцию.
Частичный ключ не обязательно является префиксом ключа, но так или иначе согласован с порядком сортировки, что позволяет выполнять не полное сканирование всех ключей, а только сканирование диапазона. Зная порядок сканирования ключей, вы можете прекратить сканирование досрочно, вернув положительное значение.
Для поддержки нечётких запросов класс операторов должен предоставлять comparePartial, а extractQuery должен выставлять флаг pmatch для частичных ключей. Дополнительную информацию смотрите в разделе Алгоритм нечёткого поиска.
Фактические типы переменных типа Datum, указанных выше, варьируются для разных классов операторов. Входное значение extractValue всегда имеет тип индексируемого столбца, а значения всех ключей имеют тип STORAGE класса операторов. Параметр query, передаваемый в extractQuery, consistent, triConsistent, будет такого типа, как правый аргумент поискового оператора; это не обязательно такой же тип, как у индексируемого столбца, главное, чтобы из него можно было извлечь ключи для поиска. Однако в SQL-объявлениях функций extractQuery, consistent, triConsistent рекомендуется указывать тип query совпадающим с типом столбца, если для разных операторов разный тип правой части.
Реализация
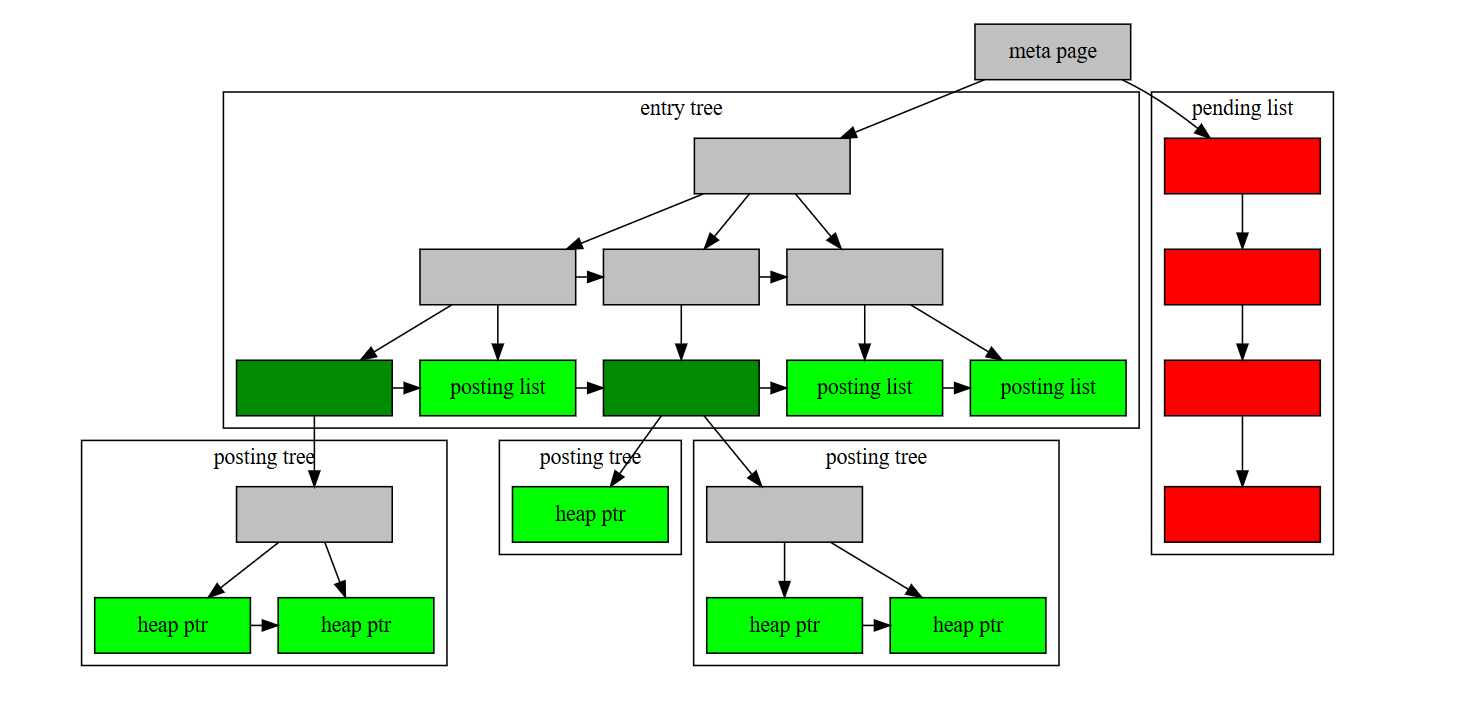
Внутри индекс GIN содержит B-дерево, построенное по ключам, где каждый ключ является элементом одного или нескольких проиндексированных объектов (например, элемент массива), и где каждая листовая вершина содержит либо массив("posting list") указателей на строки в куче (если этот массив достаточно маленький, чтобы поместиться в вершине индекса), либо указатель на B-дерево указателей кучи ("posting tree", “дерево рассылки”). На рис. 1 показаны эти компоненты индекса GIN.
В индекс может быть явно включён ключ со значением NULL. Кроме того, ключ NULL считается содержащимся во всех строках, в которых индексируемый столбец имеет значение NULL, либо если ExtractValue не выделила из значения ни одного ключа. Это сделано, чтобы можно было искать пустые значения.
Многоколоночные индексы GIN реализуются путем построения единого B-дерева, значения которого — пары (номер столбца, ключ), причём тип ключа может быть разным для разных столбцов.
Рисунок 1. Внутренняя структура GIN
Быстрое обновление GIN
Обновление индекса GIN, как правило, происходит медленно, и это неотъемлемое свойство инвертированных индексов: вставка или обновление одной строки таблицы может вызвать множество вставок в индекс (по одной для каждого ключа, извлеченного из индексируемого элемента). Ядро GIN способно отложить большую часть этой работы, вставляя новые кортежи во временный, несортированный список ожидающих записей. Когда происходит VACUUM или VACUUM ANALYZE, или когда явно вызывается функция gin_clean_pending_list, или когда длина списка ожидания превышает значение параметра gin_pending_list_limit, все кортежи из списка ожидания помещаются в основное дерево, используя метод групповой вставки, такой же как и при первичном построении индекса. Это значительно увеличивает скорость обновления индекса GIN, даже считая дополнительные накладные расходы на вакуум. Кроме того, перестроение индекса можно вынести в отдельный фоновый процесс, чтобы избежать подвисания клиента во время вставки.
Главным недостатком этого подхода является замедление поиска. Кроме обычного поиска в индексе требуется также сканировать список ожидания, поэтому большой список ожидания значительно замедлит поиск. Еще один недостаток заключается в том, что, хотя амортизированное время модификации снижается, некоторое конкретное обновление может вызывать переполнение списка ожидания и подвиснуть надолго. Обе проблемы можно свести к минимуму, правильно настроив автовакуум, или вовремя запуская gin_clean_pending_list из другого служебного процесса.
Если максимальное время модификации важнее, чем среднее, использование отложенных записей можно отключить, изменив параметр fastupdate индекса GIN. Дополнительные сведения см. в разделе Параметры хранения индекса.
Алгоритм нечёткого поиска
GIN может поддерживать запросы "нечёткого поиска", в которых
вместо конкретного ключа указывается диапазон ключей для поиска.
Диапазон всегда согласованный с порядком сортировки ключей
(определяемым методом compare, либо сортировкой по умолчанию для типа ключа), и, желательно,
чтобы он не был слишком широким.
Как бы ни звучало указание нечёткого поиска в исходном запросе,
extractQuery должна установить флаг pmatch, а в значение ключа поместить нижнюю границу
диапазона ключей. Одновременно это должно быть поддержано методом comparePartial, который должен
определить верхнюю границу диапазона поиска (например, её можно передать через extra_data).
Дерево ключей сканируется начиная с нижней границы, и пока comparePartial не вернёт > 0;
все ключи, отобранные comparePartial, считаются подходящими.
Пример для поиска ключа по префиксу очень понятный: нижняя граница диапазона ключей совпадает с префиксом, метод comparePartial получает partial_key, равный этому префиксу, и его реализация тривиальна. В общем случае нижняя и верхняя граница, и условие поиска — разные вещи, и надо как-то их все передать в comparePartial. Например, поиск слов, получающихся из 'спорт' перестановкой двух соседних букв, может потребовать сканирования диапазона ['опрст'; 'тсрпо'] или ['о'; 'у').
GIN советы и хитрости
Создание или вставка
Если вы собираетесь вставить много данных, рассмотрите вариант удаления индекса и построения его с нуля. Этот совет верен для большинства индексов, но вставка в GIN-индекс может быть особенно медленной. См. также раздел Быстрое обновление GIN.
maintenance_work_mem
Время построения GIN-индекса сильно зависит от параметра maintenance_work_mem; рассмотрите вариант увеличения этого параметра в сессии, где выполняется создание индекса.
gin_pending_list_limit
Как уже было сказано в разделе Быстрое обновление GIN, параметр gin_pending_list_limit является основным средством настройки производительности GIN-индекса (вторым по значимости средством является частота запуска автовакуума). Параметр gin_pending_list_limit можно задать отдельно для каждого индекса, изменив его параметры хранения. Общее правило, что для редко меняющихся таблиц gin_pending_list_limit должен быть меньше.
gin_fuzzy_search_limit
Основной целью разработки GIN-индексов был полнотекстовый поиск. Полнотекстовый поиск часто возвращает огромное количество строк, особенно если искать частые слова. Прочитать такое количество строк с диска и отсортировать (отранжировать) их в памяти обычно неприемлемо в нагруженной системе. Чтобы облегчить контроль таких запросов, GIN имеет настраиваемый верхний предел на количество возвращаемых строк: параметр gin_fuzzy_search_limit. По умолчанию он установлен в 0 (то есть без ограничений). Если задано ненулевое ограничение, то все результаты поиска после заданного количества молча отбрасываются. Ограничение на количество результатов является "мягким" в том смысле, что фактическое число возвращаемых результатов может несколько отличаться от указанного предела в зависимости от запроса и качества генератора случайных чисел системы.
По опыту, значения в тысячах (например, 5000 — 20000) работают хорошо.
Ограничения
GIN предполагает, что индексируемые операторы являются строгими(STRICT). Это означает, что если значение столбца NULL, то extractValue не вызывается (но создаётся запись индекса, что эта строка содержит NULL-ключ); если поисковое значение NULL, то extractQuery не вызывается и результат поиска считается пустым. Однако запрос может содержать в себе что-то, что класс операторов истолкует как поиск NULL-ключа, например, пустую строку.
Примеры
Основной дистрибутив QHB включает классы операторов GIN, ранее перечисленные в таблице в разделе Встроенные классы операторов. Следующие расширения из contrib также содержат классы операторов GIN:
-
btree_gin
Функционал B-дерева для некоторых типов данных
-
hstore
Расширение для хранения пар (ключ, значение)
-
intarray
Расширенная поддержка для int[ ]
-
pg_trgm
Сходство текста, основанное на сопоставлении триграмм