Физическое хранилище базы данных
- Структура файлов базы данных
- TOAST
- Карта свободного пространства
- Карта видимости
- Слой инициализации
- Внутренняя структура страницы базы данных
В этой главе представлен обзор формата физического хранилища, используемого базами данных QHB.
Структура файлов базы данных
В этом разделе описывается формат хранения на уровне файлов и каталогов.
Файлы конфигурации и данных, используемые СУБД, обычно хранятся в одном
каталоге называемом PGDATA (аналогично имени переменной среды).
Обычно PGDATA располагается по следующему пути: /var/lib/qhb/data.
Несколько кластеров, управляемых различными экземплярами сервера,
могут существовать на одной и той же машине.
Каталог PGDATA содержит несколько подкаталогов и управляющих файлов,
как показано в таблице 1. В дополнение к этим
необходимым элементам, файлы конфигурации кластера qhb.conf, qhb_hba.conf,
и qhb_ident.conf традиционно хранятся в PGDATA, хотя можно разместить их и
в другом месте.
Таблица 1. Содержание PGDATA
| Файл/каталог | Описание |
|---|---|
| QHB_VERSION | Файл, содержащий основной номер версии QHB |
| base | Каталог в котором содержатся подкаталоги для каждой базы данных |
| current_logfiles | Файл содержащий пути файлов для ведения журнала логгирования |
| global | Подкаталог, содержащий таблицы общие для кластера, такие как pg_database |
| pg_commit_ts | Подкаталог, содержащий данные временной метки фиксации транзакций |
| pg_dynshmem | Подкаталог, содержащий файлы, используемые динамической подсистемой общей памяти |
| pg_logical | Подкаталог, содержащий статусные данные для логического декодирования |
| pg_multixact | Подкаталог, содержащий данные о состоянии мультитранзакций (используется для общих блокировок строк) |
| pg_notify | Подкаталог, содержащий данные о состоянии LISTEN/NOTIFY |
| pg_replslot | Подкаталог, содержащий данные слота репликации |
| pg_serial | Подкаталог, содержащий информацию о совершенных сериализуемых транзакциях |
| pg_snapshots | Подкаталог, содержащий экспортированные снимки |
| pg_stat | Подкаталог, содержащий постоянные файлы для подсистемы статистики |
| pg_stat_tmp | Подкаталог, содержащий временные файлы для подсистемы статистики |
| pg_subtrans | Подкаталог, содержащий данные о состоянии подтранзакции |
| pg_tblspc | Подкаталог, содержащий символьные ссылки на табличные пространства |
| pg_twophase | Подкаталог, содержащий файлы состояний для подготовленных транзакций |
| pg_wal | Подкаталог, содержащий файлы WAL (Журнал упреждающей записи) |
| pg_xact | Подкаталог, содержащий данные о состоянии фиксации транзакций |
| qhb.auto.conf | Файл, используемый для хранения параметров конфигурации, которые задаются ALTER SYSTEM |
| postmaster.opts | Файл, записывающий параметры командной строки, с которыми сервер был запущен в последний раз |
| qhbmaster.pid | Файл блокировки, записывающий текущий идентификатор процесса postmaster (PID), путь к каталогу данных кластера, метку времени запуска postmaster, номер порта, путь к каталогу сокета Unix-домена, первый допустимый адрес listen_address (IP-адрес или * или пустой, если не прослушивает TCP), и идентификатор сегмента общей памяти (этот файл не присутствует после завершения работы сервера) |
Для каждой базы данных в кластере существует подкаталог внутри PGDATA/base, названный по номеру OID базы данных в pg_database. Этот подкаталог по умолчанию используется для файлов базы данных; в частности, там хранятся ее системные каталоги.
Обратите внимание, что в следующих разделах описано поведение встроенного устройства кучи метод доступа к таблице и методы доступа к встроенному индексу. Поскольку QHB является расширяемой системой, другие методы доступа могут работать по-другому.
Каждая таблица и индекс хранятся в отдельном файле. Для обычных отношений эти файлы называются по номеру таблицы или индекса filenode, который можно найти в pg_class.relfilenode. Но для временных отношений имя файла имеет вид tBBB_FFF, где BBB является идентификатором внутреннего сервера, который создал файл, и FFF является номером filenode. В любом случае, помимо основного файла (слоя), каждая таблица и индекс имеют карту свободного пространства (см. раздел Карта свободного пространства), в которой хранится информация о свободном пространстве, доступном в отношении. Карта свободного пространства хранится в файле с именем с номером filenode с суффиксом _fsm. Таблицы также имеют карту видимости, хранящуюся в файле с суффиксом _vm для отслеживания страниц без "мертвых" кортежей. Карта видимости описана далее в разделе Карта видимости. Незарегистрированные таблицы и индексы имеют третий файл, известный как слой инициализации с суффиксом \init (см. раздел Слой инициализации).
!!!! Предупреждение
Обратите внимание, что хотя filenode таблицы часто совпадает с ее OID, это не обязательно так. Некоторые операции, такие как усечение, переиндексация, кластеризация и некоторые формы ALTER TABLE, могут изменить filenode, сохраняя OID. Избегайте предположения, что filenode и table OID-это одно и то же. Кроме того, для некоторых системных каталогов, в частности pg_class, pg_class.relfilenode содержит ноль. Фактическое число filenode этих каталогов хранится в структуре данных более низкого уровня и может быть получен с помощью pg_relation_filenode() функция.
Если объем таблицы или индекса превышает 1 гб, он делится на сегменты размером в гигабайт. Имя файла первого сегмента совпадает с именем filenode; последующие сегменты называются filenode.1, filenode.2, и т.д. Это позволяет избежать проблем на платформах, имеющих ограничения по размеру файлов. (На самом деле, 1 гб-это только размер сегмента по умолчанию. Размер сегмента можно регулировать с помощью опции конфигурации --with-segsize при сборки QHB). В теории, для карт свободного пространства и карт видимости также может потребоваться несколько сегментов, хотя на практике это вряд ли произойдет.
Таблица, содержащая столбцы с потенциально большими записями, будет иметь связанную с ней таблицу TOAST, которая используется для внешнего хранения полей, которые слишком велики, чтобы хранить их непосредственно в строках таблицы. pg_class.reltoastrelid связывает таблицу с ее TOAST таблицами, если таковые имеются. Дополнительную информацию смотрите в разделе TOAST.
Содержание таблиц и индексов рассматривается далее в разделе Внутренняя структура страницы базы данных.
Табличные пространства делают устройство базы данных более сложным. Каждое пользовательское табличное пространство имеет символическую ссылку внутри каталога PGDATA/pg_tblspc, который указывает на физический каталог табличного пространства (т.е. расположение, указанное в команде CREATE TABLESPACE табличного пространства). Эта символьная ссылка названа по номеру OID табличного пространства. Внутри физического каталога табличных пространств есть подкаталог с именем, которое зависит от версии сервера QHB. (Этот подкаталог необходим для того, чтобы последовательные версии базы данных могли использовать одни и те же значение для CREATE TABLESPACE без конфликтов). В подкаталоге для конкретной версии для каждой базы данных, которая имеет элементы в табличном пространстве, существует подкаталог названный по номеру OID базы данных. Таблицы и индексы хранятся в этом каталоге, используя схему именования filenode. Табличное пространство pg_default недоступно через pg_tblspc, но находится в PGDATA/base. Точно так же, как pg_global табличное пространство недоступно через pg_tblspc, но находится в PGDATA/global.
pg_relation_filepath() функция показывает весь путь (относительно
PGDATA) любого отношения. Это часто полезно в качестве альтернативы для
запоминания многих из вышеперечисленных правил. Но имейте в виду, что
эта функция просто дает название первого сегмента основного слоя
отношения — вам может понадобиться добавить номер сегмента и/или
_fsm, _vm, или _init чтобы найти все файлы,
связанные с этим отношением.
Временные файлы (для таких операций как сортировка данных большего размера, чем может поместиться в памяти) создаются внутри PGDATA/base/pgsql_tmp, или в подкаталоге табличного пространства внутри pgsql_tmp, если табличное пространство отличается от pg_default. Имя временного файла имеет вид pgsql_tmpPPP.NNN, где PPP это PID владеющего бэкенда и NNN идентифицирует различные временные файлы этого бэкенда.
TOAST
В этом разделе представлен обзор TOAST (The Oversized-Attribute Storage Technique, техника хранения сверхбольших атрибутов).
QHB использует фиксированный размер страницы (обычно 8 кб) и не позволяет кортежам занимать несколько страниц. Поэтому невозможно хранить очень большие значения полей непосредственно. Чтобы преодолеть это ограничение, большие значения полей сжимаются и/или разбиваются на несколько физических строк. Это происходит прозрачно для пользователя, только с небольшим влиянием на большую часть внутреннего кода. Этот прием называют TOAST. Инфраструктура TOAST также используется для улучшения обработки больших значений данных в памяти.
Только некоторые типы данных поддерживают TOAST — нет необходимости накладывать накладные расходы на типы данных, которые не могут создавать большие значения полей. Для поддержки TOAST тип данных должен иметь представление переменной длины (varlena), в котором обычно первое четырехбайтовое слово содержит общую длину значения в байтах (включая сам размер). TOAST не ограничивает остальную часть представления типа данных. Специальные представления работают путем изменения или интерпретации этого начального слова длины. Поэтому функции уровня C/RUST, использующие тип данных, поддерживающий TOAST, должны быть аккуратны с тем, как они обрабатывают входные значения TOAST: входные данные могут фактически не состоять из четырехбайтового слова длины и содержимого до тех пор, пока они не будут детализированы. (Обычно это делается путем вызова PG_DETOAST_DATUM прежде, чем делать что-либо с входным значением, но в некоторых случаях возможны более эффективные подходы. Дополнительную информацию смотрите в разделе Использование TOAST).
TOAST использует два бита из длины слова varlena (биты старшего порядка на big-endian архитектурах и биты младшего порядка на little-endian архитектурах), тем самым ограничивая логический размер любого значения типа данных с поддержкой TOAST до 1 гб (230 - 1 байт). Когда оба бита равны нулю, значение является обычным значением соответствующего типа данных, а оставшиеся биты длины содержат общий размер типа данных (включая размер типа длины) в байтах. Когда выставлен бит самого старшего или самого младшего порядка, значение имеет только однобайтовый заголовок вместо обычного четырехбайтового заголовка, а оставшиеся биты этого байта дают общий размер типа данных (включая байт длины) в байтах. Этот подход предоставляет экономичное хранение значений размером менее 127 байт, но при этом позволяет увеличить тип данных до 1 гб при необходимости. Значения с однобайтовыми заголовками не выровнены по какой-либо определенной границе, тогда как значения с четырехбайтовыми заголовками выровнены по крайней мере по четырехбайтовой границе; это отсутствие выравнивания обеспечивает дополнительную экономию пространства, что значительно для коротких значений. В частном случае, если все оставшиеся биты однобайтового заголовка равны нулю (что было бы невозможно для самодостаточной длины), значение является указателем на исходные данные с несколькими возможными альтернативами, как описано ниже. Тип и размер такого а TOAST-указателя определяется кодом, хранящимся во втором байте данных. Наконец, когда бит самого старшего или самого младшего порядка равен нулю, а соседний бит установлен, то содержимое данных сжато и должно быть распаковано перед использованием. В этом случае оставшиеся биты четырехбайтового слова длины дают общий размер сжатых данных, а не исходные данные. Обратите внимание, что сжатие также возможно для данных разделенных на несколько страниц. Это определяется не заголовком varlena, а содержимым по TOAST-указателю.
Как уже упоминалось, существует несколько типов данных для TOAST указателя. Наиболее распространенный тип — это указатель на разделенные по страницам данные, хранящиеся в таблице TOAST. Эта таблица отделена от таблицы, содержащая TOAST-указатель на данные, но связана с ней. Эта информация указателя на диске создается с помощью кода управления TOAST (в access/heap/tuptoaster.c) когда кортеж, который будет храниться на диске, слишком велик, чтобы быть сохраненным как есть. Более подробная информация приводится в разделе Внешнее хранилище TOAST на диске. Кроме того, TOAST-указатель на данные может содержать указатель на исходящие данные, которые отображаются в другом месте в памяти. Такие данные обязательно временны и никогда не появляются на диске, но они очень полезны для предотвращения копирования и избыточной обработки больших значений данных. Более подробная информация приводится в разделе Внешнее хранилище TOAST в памяти.
Метод сжатия, используемый как для одностраничных, так и для многостраничных данных, является довольно простой и очень быстрой реализацией алгоритма из семейства методов сжатия LZ, реализация представлена в src/common/pg_lzcompress.c.
Внешнее хранилище TOAST на диске
Если любой из столбцов таблицы поддерживает TOAST, таблица будет иметь связанную таблицу TOAST, OID которой хранится в записи таблицы pg_class.reltoastrelid. Значения TOAST на диске хранятся в таблице TOAST, как описано ниже более подробно.
Разделенные значения делятся (если используется сжатие) на порции длиной не более чем TOAST_MAX_CHUNK_SIZE байт (по умолчанию это значение выбрано таким образом, что четыре строки chunk поместятся на странице, что составляет около 2000 байт). Каждый фрагмент хранится в виде отдельной строки в таблице TOAST, принадлежащей таблице-владельцу. Каждая таблица TOAST имеет столбцы chunk_id (OID, определяющий конкретное TOAST значение), chunk_seq (порядковый номер для фрагмента в пределах его значения), и chunk_data (фактические данные фрагмента). Уникальный индекс на chunk_id и chunk_seq обеспечивает быстрое доступ к значениям. Таким образом, указатель на данные, представляющий собой устаревшее значение на диске, должен хранить OID таблицы TOAST, в которой нужно искать, и OID конкретного значения (его chunk_id). Для удобства, указатели на данные также хранят логический размер данных (исходная несжатая длина) и физический сохраненный размер (различен, если сжатие было применено). Учитывая байты заголовка varlena, общий размер TOAST-указателя на диске составляет 18 байт независимо от фактического размера представленного значения.
Код для обработки TOAST запускается только тогда, когда значение строки,
подлежащее хранению в таблице, больше, чем TOAST_TUPLE_THRESHOLD байт
(обычно 2 кб). Код TOAST будет сжимать и/или перемещать значения полей
из строки до тех пор, пока значение строки не станет короче, чем
TOAST_TUPLE_TARGET байт (также 2 кб по-умолчанию) или до тех пор,
пока объем строки будет невозможно уменьшить. Во время операции UPDATE
значения неизмененных полей обычно сохраняются как есть; поэтому
обновление строки с значениями разделенных на несколько страниц не несет никаких
дополнительных затрат, если ни одно из таких значений не
изменилось.
Код для обработки TOAST определяет четыре различных стратегии для хранения столбцов с поддержкой TOAST на диске:
-
PLAIN предотвращает сжатие или хранение вне строки; кроме того, он отключает использование однобайтовых заголовков для типов varlena. Это единственная возможная стратегия для столбцов типов данных, не допускающих TOAST.
-
EXTENDED позволяет как сжатие, так и хранение вне строки. Это значение по умолчанию для большинства типов данных с поддержкой TOAST. Сначала будет предпринята попытка сжатия, затем хранение вне строки, если строка все еще слишком велика.
-
EXTERNAL позволяет хранить вне строки, но не сжимать. Использование EXTERNAL сделает операции с подстрокой в больших text и bytea столбцах быстрее (в ущерб большему требованию к памяти), потому что такие операции оптимизированы для выборки только необходимых частей вне строки, когда оно не сжато.
-
MAIN позволяет сжатие, но не вне хранилища. (На самом деле, для таких столбцов по-прежнему будет выполняться автономное хранение, но только в крайнем случае, когда нет другого способа сделать строку достаточно маленькой, чтобы поместиться на странице).
Каждый тип данных поддерживающий TOAST задает стратегию по умолчанию для столбцов этого типа данных. Также стратегию для указанного столбца таблицы можно изменить с помощью ALTER TABLE ... SET STORAGE.
TOAST_TUPLE_TARGET можно настроить для каждой таблицы с помощью ALTER TABLE ... SET (toast_tuple_target = N)
По сравнению с более простым подходом, который позволяет значениям строк пересекать границы странцы, эта схема имеет ряд преимуществ. Предполагая, что запросы обычно имеют сравнения с относительно маленькими значениями ключа, большая часть работы будет выполнена с использованием записи основной строки. Большие значения TOAST-атрибутов будут извлечены только (если они вообще выбраны) во время отправки результата клиенту. Таким образом, основная таблица намного меньше, а значит больше строк помещается в общий буферный кэш, чем могло быть без использования внешнего хранения аттрибутов. Данные для сортировки также уменьшаются, и сортировка чаще всего будет выполняться полностью в памяти. Небольшой тест показал, что в таблице, которая содержит типичные HTML-страницы и их URL-адреса, хранится примерно в два раза меньший объем необработанных данных, включая таблицу TOAST, и что основная таблица содержит только около 10% всех данных (URL-адреса и некоторые небольшие HTML-страницы). При этом не было никакой разницы во времени выполнения по сравнению с таблицей без TOAST аттрибутов, в которой все HTML-страницы были сокращены до 7 КБ, для соответствия.
Внешнее хранилище TOAST в памяти
TOAST-указатели могут указывать на данные, которые не находятся на диске, а находятся в другом месте в памяти текущего серверного процесса. Такие указатели, очевидно, не могут быть долговечными, но они тем не менее полезны. В настоящее время существует два вида: указатели на косвенные (indirect) данные и указатели на расширенные (expanded) данные.
Косвенный указатель TOAST указывает на значение varlena, хранящееся где-то в памяти. Изначально он был создан просто как доказательство концепции, но в настоящее время он используется во время логического декодирования, чтобы избежать потенциального создания физических кортежей более 1 гб (что может произойти при объединении всех разделенных полей в один кортеж). У такого способа весьма ограниченное применение: владелец такого указателя самостоятельно должен учитывать, что ссылаемые данные существуют до тех пор, пока существует указатель.
Расширенные TOAST-указатели полезны для сложных типов данных, представление которых на диске не особенно подходит для вычислительных целей. Например, стандартное представление varlena массива включает информацию о размерности, битовый массив с null-значениями, если таковые имеются и далее все значения по порядку. Когда сам тип элемента имеет переменную длину, единственный способ найти N-ный элемент — это просмотреть все предыдущие элементы. Такое представление подходит для хранения на диске из-за его компактности, но для вычислений с массивом гораздо лучше иметь “расширенное” или “деконструированное” представление, в котором определены все начальные местоположения элементов. Механизм TOAST-указателя поддерживает эту потребность, позволяя данным, переданным по ссылке, указывать либо на стандартное значение varlena (представленного на диске), либо на TOAST-указатель, который указывает на расширенное представление где-то в памяти. Детали этого расширенного представления зависят от типа данных, тем не менее он должен иметь стандартный заголовок и соответствовать другим требованиям API, приведенным в src/include/utils/expandeddatum.h. функции уровня C/RUST, работающие с типом данных, могут выбрать для обработки любое представление. Функции, которые не знают о расширенном представлении, а просто применяют PG_DETOAST_DATUM к их входам будет, прозрачно получают обычное представление varlena; поэтому поддержка расширенного представления может вводиться постепенно, по одной функции за раз.
Указатели TOAST на расширенные значения далее разбиваются на указатели для чтения-записи и только для чтения. Представление с указанием на объект является одинаковым в любом случае, но функция, получающая указатель на чтение и запись, может изменять указанное значение на месте, тогда как функция, получающая указатель только на чтение, не должна этого делать; она должна сначала создать копию, если она хочет сделать измененную версию значения. Это различие и некоторые связанные с ним соглашения позволяют избежать ненужного копирования расширенных значений во время выполнения запроса.
Для всех типов указателей TOAST в памяти код управления TOAST гарантирует, что никакие данные указателя не может оказаться на диске. Указатели TOAST в памяти автоматически расширяются до обычных линейных значений varlena перед хранением, и затем, возможно, преобразуются в указатели TOAST на диске, если содержащийся кортеж был слишком большим.
Карта свободного пространства
Каждое отношение кучи и индекса, за исключением хэш-индексов, имеет карту свободного пространства (FSM) для отслеживания доступного пространства в отношении. Она хранится вместе с основными данными отношения в отдельном слое отношений, названной по номеру filenode отношения вместе с _fsm суффиксом. Например, если filenode отношения равен 12345, то FSM хранится в файле с именем 12345_fsm, в том же каталоге, что и основной файл отношения.
Карта свободного пространства организована в виде дерева страниц FSM. Страницы FSM нижнего уровня хранят свободное пространство, доступное на каждой странице кучи (или индекса), используя один байт для представления каждой такой страницы. Верхние уровни агрегируют информацию с нижних уровней.
Внутри каждой страницы FSM находится двоичное дерево, хранящееся в массиве с одним байтом на узел. Каждый конечный узел представляет собой страницу кучи или страницу FSM более низкого уровня. В каждом не-листовом узле хранится максимум из его дочерних значений. Поэтому максимальное значение всех листовых узлах хранится в корне.
Посмотрите src/backend/storage/freespace/README для получения более подробной информации о том, как структурирован FSM, и как он обновляется и ищется. Модуль pg_freespacemap может использоваться для изучения информации, хранящейся на картах свободного пространства.
Карта видимости
Каждое отношение кучи имеет карту видимости (VM), чтобы отслеживать, какие страницы содержат только кортежи, которые, как известно, видны для всех активных транзакций; она также отслеживает, какие страницы содержат только замороженные кортежи. Она хранится вместе с основными данными отношения в отдельном слое отношений, названной по номеру filenode отношения вместе с _vm суффиксом. Например, если filenode отношения равен 12345, то VM хранится в файле с именем 12345_vm, в том же каталоге, что и основной файл отношения. Обратите внимание, что индексы не имеют карту видимости.
Карта видимости хранит два бита на странице кучи. Первый бит, если он установлен, указывает, что страница является полностью видимой, или другими словами, что страница не содержит никаких кортежей, которые необходимо очистить. Эта информация также может использоваться сканированиями по индексу для ответа на запросы, с использованием только кортежа индекса. Второй бит, если он установлен, означает, что все Кортежи на странице были заморожены. Это означает, что даже вакуум с защитой от переполнения счетчика транзакции не должен повторно просматривать страницу.
Карта является консервативной в том смысле, что мы удостоверяемся, что всякий раз, когда бит установлен, мы знаем, что условие истинно, но если бит не установлен, он может быть или не быть истинным. Биты карты видимости задаются только вакуумом, но очищаются любыми операциями изменения данных на странице.
Модуль pg_visibility можно использовать для изучения информации, хранящейся в карте видимости.
Слой инициализации
Каждая нежурналируемая таблица и каждый индекс нежурналируемой таблицы имеют слой инициализации. Слой инициализации — это пустая таблица или индекс соответствующего типа. Когда нежурналируемая таблица должна быть сброшена к пустому состоянию из-за сбоя, слой инициализации копируется поверх основного слоя, а все другие слои стираются (они будут автоматически воссозданы по мере необходимости).
Внутренняя структура страницы базы данных
В этом разделе представлен обзор формата страницы, используемого в таблицах и индексах QHB1. Последовательности и таблицы TOAST представляются так же, как обычная таблица.
В следующем объяснении предполагается, что байт содержит 8 битов. Кроме того, термин элемент относится к значению данных, которое хранится на странице. В таблице элемент является строкой; в индексе элемент является записью индекса.
Каждая таблица и индекс хранятся в виде массива страниц фиксированного размера (обычно 8 кб, хотя при компиляции сервера можно выбрать другой размер страницы). В таблице все страницы логически эквивалентны, поэтому определенный элемент (строка) может храниться на любой странице. В индексах первая страница обычно зарезервирована как метастраница, содержащая управляющую информацию, и в индексе могут быть разные типы страниц, в зависимости от метода доступа к индексу.
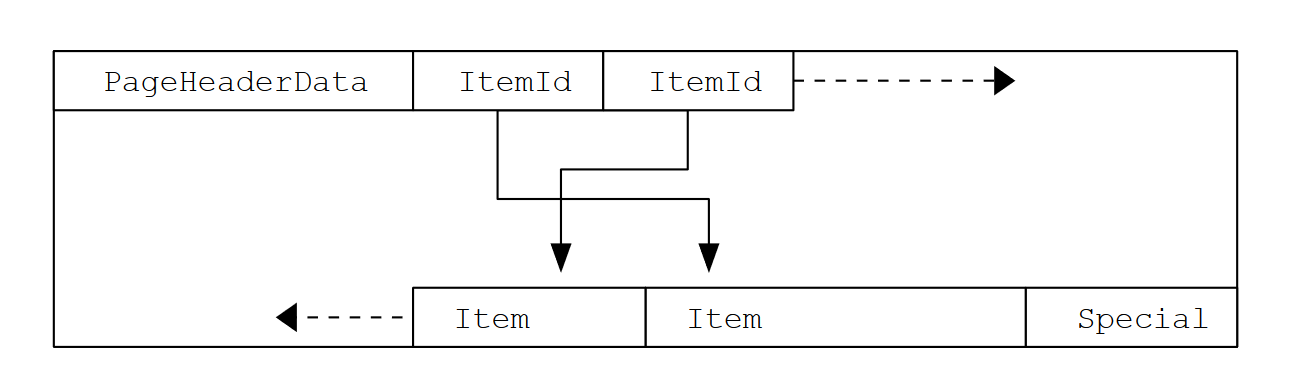
В таблице 2 показана общая компоновка страницы. На каждой странице есть 5 частей.
Таблица 2. Общая Структура Страницы
| Предмет | Описание |
|---|---|
| PageHeaderData | 24 байта длиной. Содержит общую информацию о странице, включая указатели на свободное места. |
| ItemIdData | Массив идентификаторов элементов, указывающих на фактические элементы. Каждая запись является парой (смещение,длина). 4 байта на элемент. |
| Free space | Свободное пространство. Новые идентификаторы элементов выделяются с начала этой области, новые элементы — с конца. |
| Items | Собственно сами элементы. |
| Special space | Специальная область для методов индексного доступа. Различные методы хранят различные данные. Пустое поле для обычных таблиц. |
Первые 24 байта каждой страницы состоят из заголовка страницы (PageHeaderData). Его формат подробно описан в таблице 3. Первое поле отслеживает самую последнюю запись WAL, связанную с этой страницей. Второе поле содержит контрольную сумму страницы, если контрольные суммы включены. Далее идет 2-байтовое поле, содержащее биты флагов. Далее следуют три 2-байтных целочисленных поля (pd_lower, pd_upper, и pd_special). Они содержат смещения в байтах от начала страницы до начала свободного пространства, до конца свободного пространства и до начала специального пространства. Следующие 2 байта заголовка страницы, pd_pagesize_version, содержат размер страницы и индикатор версии.
Размер страницы в основном присутствует только в качестве перекрестной проверки; нет поддержки страниц разных размеров при установке. Последнее поле служит подсказкой для того, будет ли полезно очистить страницу: он отслеживает самый старый XMAX на странице, из тех что не был очищен.
Таблица 3. Структура PageHeaderData
| Поле | Тип | Длина | Описание |
|---|---|---|---|
| pd_lsn | PageXLogRecPtr | 8 байт | LSN: следующий байт после последнего байта WAL-записи для последнего изменения на этой странице |
| pd_checksum | uint16 | 2 байта | Контрольная сумма страницы |
| pd_flags | uint16 | 2 байта | Биты флагов |
| pd_lower | LocationIndex | 2 байта | Смещение до начала свободного места |
| pd_upper | LocationIndex | 2 байта | Смещение до конца свободного пространства |
| pd_special | LocationIndex | 2 байта | Смещение до начала специального пространства |
| pd_pagesize_version | uint16 | 2 байта | Размер страницы и номер версии макета информация |
| pd_prune_xid | TransactionId | 4 байта | Самый старый неочищенный XMAX на странице, или ноль, если отсутствует |
Все подробности можно узнать в разделе src/include/storage/bufpage.h.
После заголовка страницы идут идентификаторы элементов (ItemIdData), каждый из которых требует четыре байта. Идентификатор элемента содержит смещение в байтах до начала элемента, его длину в байтах и несколько битов атрибутов, влияющих на его интерпретацию. Новые идентификаторы элементов выделяются по мере необходимости с начала свободного пространства. Количество присутствующих идентификаторов элементов можно определить, посмотрев на pd_lower, который увеличивается при выделении нового идентификатора. Поскольку идентификатор элемента никогда не перемещается до тех пор, пока он не будет освобожден, его индекс можно использовать в долгосрочной основе для ссылки на элемент, даже если сам элемент перемещается по странице для сжатия свободного пространства. На самом деле, каждый указатель на элемент (ItemPointer, также известный как CTID) созданный QHB состоит из номера страницы и индекса идентификатора элемента.
Сами элементы хранятся в пространстве, выделенном с конца свободного пространства. Точная структура варьируется в зависимости от того, что должна содержать таблица. В таблицах и последовательностях используется структура с именем HeapTupleHeaderData, описанная ниже.
Последний раздел - это "специальный раздел", который может содержать все, что метод доступа желает сохранить. Например, B-дерево хранит ссылки на левый и правый родственные элементы страницы, а также некоторые другие данные, относящиеся к структуре индекса. Обычные таблицы вообще не используют специальный раздел (указывается при настройке pd_special для выравнивания размера страницы).
На рис. 1 показано, как эти части располагаются на странице.
Рис. 1. Структура страницы
Расположение Строк Таблицы
Все строки таблицы структурированы аналогичным образом. Существует заголовок фиксированного размера (занимающий 23 байта на большинстве машинах), за которым следует необязательное битовый массив с null-элементами, необязательное поле с идентификатором объекта и пользовательские данные. Заголовок подробно описан в таблице 4. Сами же пользовательские данные (столбцы строки) начинаются со смещения, указанного в t_hoff, который всегда должен быть кратен MAXALIGN для платформы. Битовый массив с null-элементами присутствует только в том случае, если установлен бит HEAP_HASNULL в t_infomask. Если он присутствует, то он начинается сразу после фиксированного заголовка и занимает достаточно байт, чтобы иметь один бит на столбец данных (т.е. количество битов, равное количеству атрибутов в столбце). t_infomask2). В этом списке битов выставленный бит указывает, что элемент не null, пустой - null. Когда битовый массив отсутствует, все столбцы считаются не null. Идентификатор объекта присутствует только в том случае, если установлен бит HEAP_HASOID_OLD в t_infomask. Если присутствует, то он появляется непосредственно перед смещением t_hoff. Чтобы сделать t_hoff кратным MAXALIGN между битовым массивом и идентификатором объекта добавляется отступ произвольного размера. (Это в свою очередь гарантирует, что идентификатор объекта соответствующим образом выровнен.)
Таблица 4. Структура Heaptupleheaderdata
| Поле | Тип | Длина | Описание |
|---|---|---|---|
| t_xmin | TransactionId | 4 байта | значение XID при вставке |
| t_xmax | TransactionId | 4 байта | значение XID при удалении |
| t_cid | CommandId | 4 байта | значение CID при вставке и/или удалении (пересекается с t_xvac) |
| t_xvac | TransactionId | 4 байта | XID для операции вакума при перемещении версии строки |
| t_ctid | ItemPointerData | 6 байт | TID текущий или более новой версии строки |
| t_infomask2 | uint16 | 2 байта | количество атрибутов плюс различные флаговые биты |
| t_infomask | uint16 | 2 байта | различные флаговые биты |
| t_hoff | uint8 | 1-байтовый | смещение до данных пользователя |
Все подробности можно узнать в разделе src/include/access/htup_details.h.
Интерпретация фактических данных может быть выполнена только с помощью информации, полученной из других таблиц, в основном pg_attribute. Ключевые значения, необходимые для определения местоположения полей: attlen и attalign. Доступ к произвольному атрибуту возможен только тогда, когда все поля имеют фиксированную длину и нет нулевых значений. Все эти особенности определены в функциях heap_getattr, fastgetattr и heap_getsysattr.
Чтобы прочитать данные, необходимо прочитать каждый атрибут по очереди. Первым делом нужно проверить, является ли поле NULL в соответствии с битовым массивом null-значений. Если это так, то элемент отсутствует в данных. После этого необходимо убедиться, что есть правильное выравнивание. Если поле имеет фиксированную ширину, то все байты помещаются как есть. Если это поле переменной длины (attlen = -1), то это немного сложнее. Все типы данных переменной длины имеют общую структуру заголовка struct varlena, который включает в себя общую длину сохраненного значения и некоторые флаговые биты. В зависимости от флагов, данные могут быть либо встроенными, либо хранится отдельно в таблице TOAST; они также могут быть сжаты (см. раздел TOAST).
На самом деле, использование этого формата страницы не требуется ни для методов доступа к таблице, ни для методов доступа к индексу. Метод heap доступа к таблице всегда использует этот формат. Все существующие методы индексирования также используют базовый формат, но данные, хранящиеся на мета-страницах индекса, обычно не следуют правилам компоновки элементов.